
Prompt: ai agents, cubism, knowledge work, minimalism, white background, pastels
Context Engineering For Developers: Build Smarter AI Agents with the FACT Framework
 Gareth Cull
Gareth Cull
- What is an AI Agent? An AI agent is an evolved form of AI that goes beyond simple Q&A. Unlike traditional LLMs, agents have memory, maintain chat history, and can access tools and APIs to take real actions - making them true working partners rather than just information sources.
- What is Context Engineering? Context engineering is the discipline of equipping AI agents with the right information at the right time. It focuses on building comprehensive knowledge bases that help agents understand your specific business context, data, and goals - transforming them from generic responders into domain-aware partners.
- What is the FACT Framework? FACT is a practical framework for structuring context that ensures AI agents can effectively understand and use your data. It consists of four key elements: Framing (clear boundaries), Attributes (metadata and usage), Chronology (temporal context), and Transformation (AI-optimized formatting).
- Are there any pre-requisites for this article? This guide is designed for developers, data engineers, and technical product managers who want to build smarter AI agents. You should have basic familiarity with LLMs and Python programming. If you're looking to move beyond simple chatbots to create AI agents that truly understand your business data, this article will show you how.
Introduction
For years, prompt engineering has been the go-to technique for getting better results from LLMs.
But what if the real magic isn't just in the prompt, but in what the AI already knows before you even ask?
Welcome to Context Engineering.
This isn't just about giving an LLM a few lines of text or some data to analyze; it's about providing a comprehensive, dynamic, and relevant knowledge base to draw from. One that is grounded in data and allows an AI Agent to truly understand your unique business perspective. For developers and product teams building AI-powered tools, understanding context engineering is the key to moving beyond generic LLM responses to truly intelligent, personalized AI agents.
In this guide, we'll explore the differences between LLMs and AI agents, dive deep into context engineering, and introduce the FACT Framework for context engineering. I'll also walk through a practical example of how I'm implementing FACT within an Analytics Agent that unifies multiple data sources as context into a single intelligent interface.
Given that context engineering is such a new area, I'd love to hear your thoughts on the FACT approach and how we can collectively push this field forward.
To get the most out of this guide, I assume you have experience with prompt engineering and some python programming. So if this is you or you are interested in these areas, please read on!
Now let's dive in and build smarter Agents!
Table of Contents
This guide will cover the following:
- What is an AI Agent?
- What is Context Engineering?
- How is Context Engineering Different from Prompt Engineering?
- What are Some Challenges with Context Engineering?
- A Real World Implementation: Building an AI Agent with Context Engineering
- The FACT Framework: Structuring Context for Data Sources
- Conclusion
Before we dive into the wonderful world of context engineering, let's briefly touch on what an AI Agent is.
What is an AI Agent?
AI agents represent a fundamental shift in how we interact with artificial intelligence.
Unlike traditional LLMs that simply respond to queries, AI agents have the ability to take actions, remember context, and work toward specific goals over time. This evolution from passive Q&A chatbot to active problem-solving agent marks a new era where AI becomes a true working partner, and not just an information source.
And to work most effectively, AI agents need three core capabilities:
- Memory: to store and recall information from previous interactions, Agents build knowledge over time rather than starting fresh each conversation
- Chat History: Full context of your ongoing conversations, to ensure they understand the context of not just what you're asking now, but what you've discussed before
- Access to Tools & APIs: Connections to external systems (using APIs or Model Context Protocol) that enable Agents take real action such as searching the web or pulling data from the Google Analytics API
Agents can work autonomously, with other agents, or with a human in the loop.
Personally, I prefer keeping humans at the center because agents still benefit from our guidance on complex decisions and edge cases. By combining AI's speed and scale with human judgment and creativity, we truly get the best of both worlds. And as these agents evolve, they'll naturally earn more autonomy and trust through increased capabilities. But for now, they shine brightest as humanity's collaborative partners rather than solo performers.
What is Context Engineering?
Context engineering is the emerging discipline of equipping AI agents with the right information at the right time, transforming them from generic responders into true business partners who understand your specific customer needs, data and business context.
Think of it this way: An LLM is like a brilliant data consultant who shows up with no context about your business. With context engineering, we can transform that consultant into someone who's been embedded in your company for years. They understand your goals, know your metrics and have all of your data at their fingertips.
The goal of implementing context into your agent should be to create an AI that feels like it truly understands your specific business context, not just general concepts.
To build this kind of intelligent agent, you need to enable it to:
- Store and retrieve relevant data: Building memory systems that recall past interactions and insights
- Understand user history and preferences: Learning from chat engagement and conversation patterns
- Curate domain-specific knowledge: Incorporating product positioning, metric definitions, business logic, etc.
- Improve over time: Adapting to new data patterns and evolving business realities
With these capabilities in place, your AI agent becomes domain-aware. It can generate responses that feel tailored to your specific business needs and situation rather than generic advice.
How is Context Engineering Different from Prompt Engineering?
While both improve AI performance, they fundamentally solve different problems:
Prompt engineering focuses on crafting the perfect question or instruction—optimizing word choice, structure, and format to get better responses. It asks: "How do I phrase this request?"
Context engineering focuses on what the AI knows before you even ask—curating memories, data sources, business rules, and user history. It asks: "What background knowledge should my AI have?"
Think of it this way...
- Prompt engineering is asking the right question about your data
- Context engineering is having all your dashboards, historical trends, and metric definitions already loaded.
Both work together, but context engineering is what transforms one-off interactions into intelligent, ongoing partnerships.
What Are Some Challenges with Context Engineering?
Of course, transforming AI into intelligent partners through context engineering isn't without its challenges.
Managing token limits (even those with 1M+ context windows), battling latency (loading extensive context can really slow down analysis), and ensuring data freshness are top of mind when building a contextual agent. Not only that, add in the complexity of integrating multiple data sources while maintaining personalized context at scale, and you've got yourself some serious technical challenges!
The key is finding the right balance: enough context to be intelligent, but not so much that it slows down or confuses the AI.
A Real World Implementation: Building an AI Agent with Context Engineering
Let's bring this all together with a real world example. I'll walk through how I built a Product Growth Analytics Agent that unifies multiple data sources into a single, intelligent interface.
As part of this implementation walk-through, I'll also introduce you to the FACT framework, which is my current way of structuring data as context for an AI Agent.
The Problem: Siloed Analytics
If you're like me, you probably have data living in multiple platforms and different user experiences:
- Google Analytics for web and app metrics
- Survey Tools for customer and product feedback
- Experiment Platforms to help you manage your A/B Tests
- UX Data for designs, wireframes and prototypes
All of these data sources tell a unique piece of your product's story and performance. Measurement is often split up between teams, with different stakeholders accessing datasets independently. But what if we could unify all this data and query it conversationally through a single AI agent?
From Single-Purpose to Multi-Context Agents
I've been building analytics agents for a while now. My finely tuned Google Analytics agent has become a great collaborator - I love asking it ad hoc questions and use its AI-generated dashboards daily. But I kept hitting the same limitation: it could only see one slice of my product's story.
I wanted an agent that could simultaneously understand all of the data sources in my product analytics stack, in addition to all of the conversations had about growing the product. I wanted a true product partner. Not just an LLM. An Agent that understands my business with access to my data so it can help me optimize and grow my product.
This was a big challenge that wasn't just technical.
It was conceptual.
How do you organize diverse data types into a coherent context that an AI can understand and reason about?
The Solution: Dashboard-First Context Engineering
As a data professional, I realized the answer was hiding in plain sight: dashboards! They're already how we organize complex, multi-source data for human consumption. Why not use the same mental model for AI?
I would just need to come up with a way to not overwhelm the model with datasets, but craft context with simplified views of datasets and descriptions about what each dataset is and how to use it.
So, the data pipelines for this Product Growth Dashboard experience would need to look like this:
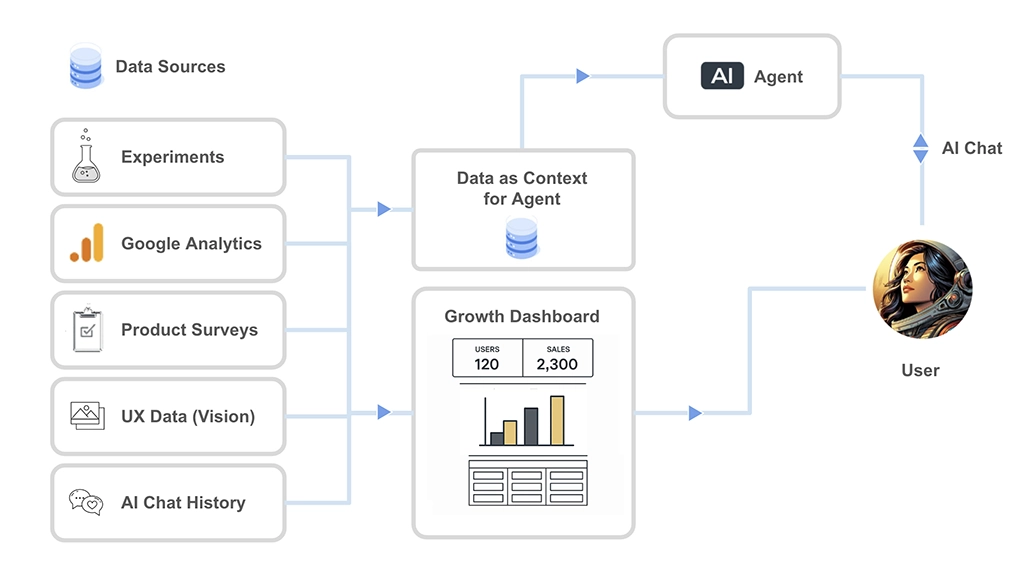
A high level data pipeline for the PGD Experience
Now to start building!
My Four-Step Approach to Building this Agentic Experience
I broke this project up into 4 steps:
- Mockup a unified dashboard with AI and start to understand how all these data sources connect
- Build the dashboard with real APIs - ensuring data quality and structure
- Create a comprehensive system message to help the agent understand the datasets it will have access to
- Engineer context documentation for each data source to maximize AI Agent comprehension
Now let me go into each of these steps in a bit more detail.
Step 1: Prototyping the Vision
I started by using Prototypr.ai Studio to mockup a dashboard that could display all my data sources cohesively. I had recently integrated Gemini 2.5 Pro into the platform and it did a fairly good job at generating a first draft.
At this stage, i actually had a pretty good idea of how i wanted to structure the dashboard. But, I wanted to flush out the experimentation side of things and see how Gemini would structure a growth marketing dashboard. So, this is what that looked like:
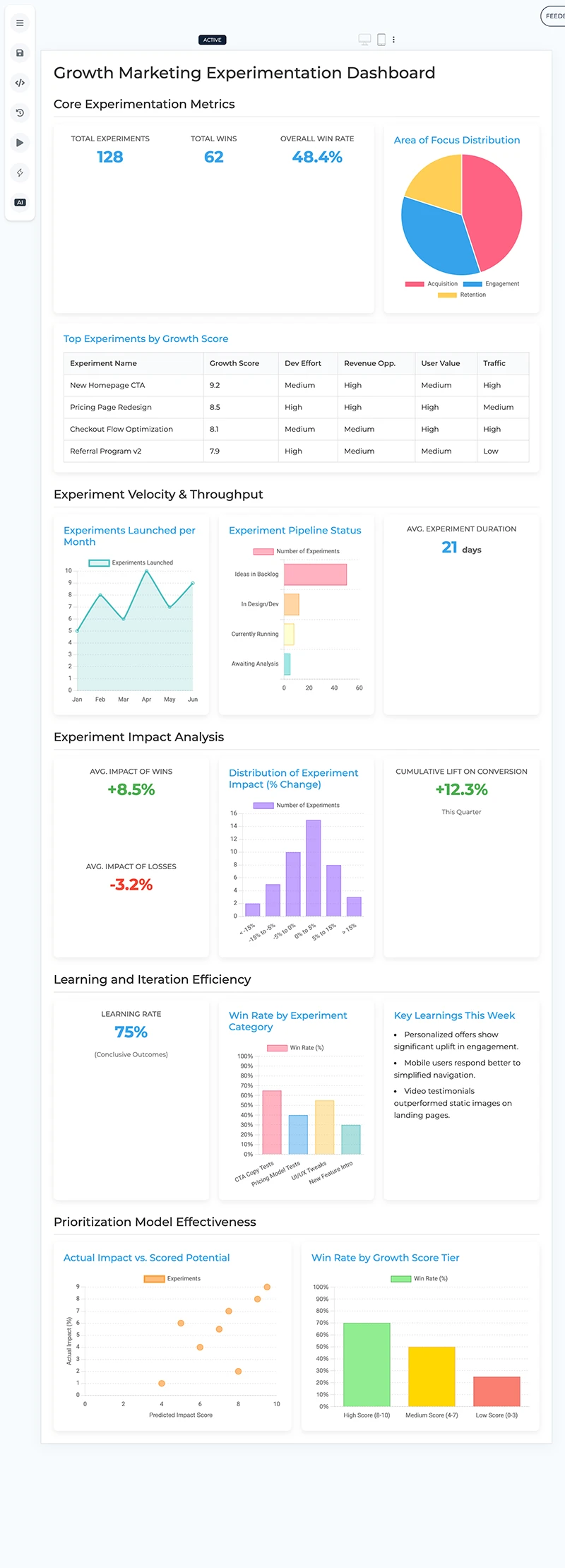
An early dashboard prototype built with Google Gemini 2.5 Pro
A few of the Experiment KPIs and charts such as Win Rate by Category made it through to the final design. Overall, I'd say prototyping a dashboard with AI was a good use of time since Gemini offered some really good ideas for what to include in the final design.
Step 2: Building the Real Dashboard
One of the key insights from the dashboard prototyping phase was that the dashboard really should be actionable. It should be structured around the product development lifecycle and how I'm going to work. Alsmost like a product management analytics tool, with an AI Agent that sits on top.
Everything you select to measure or add to the dashboard helps create a unique agent that understands your business and approach to growing your product. The goal was to see the impact of my product development efforts on the KPIs through the decisions I make with the experiemnts that i run to grow my product.
So, the dashboard started with activity and experimentation, flow into KPIs, and conclude with qualitative feedback. It looked like this:
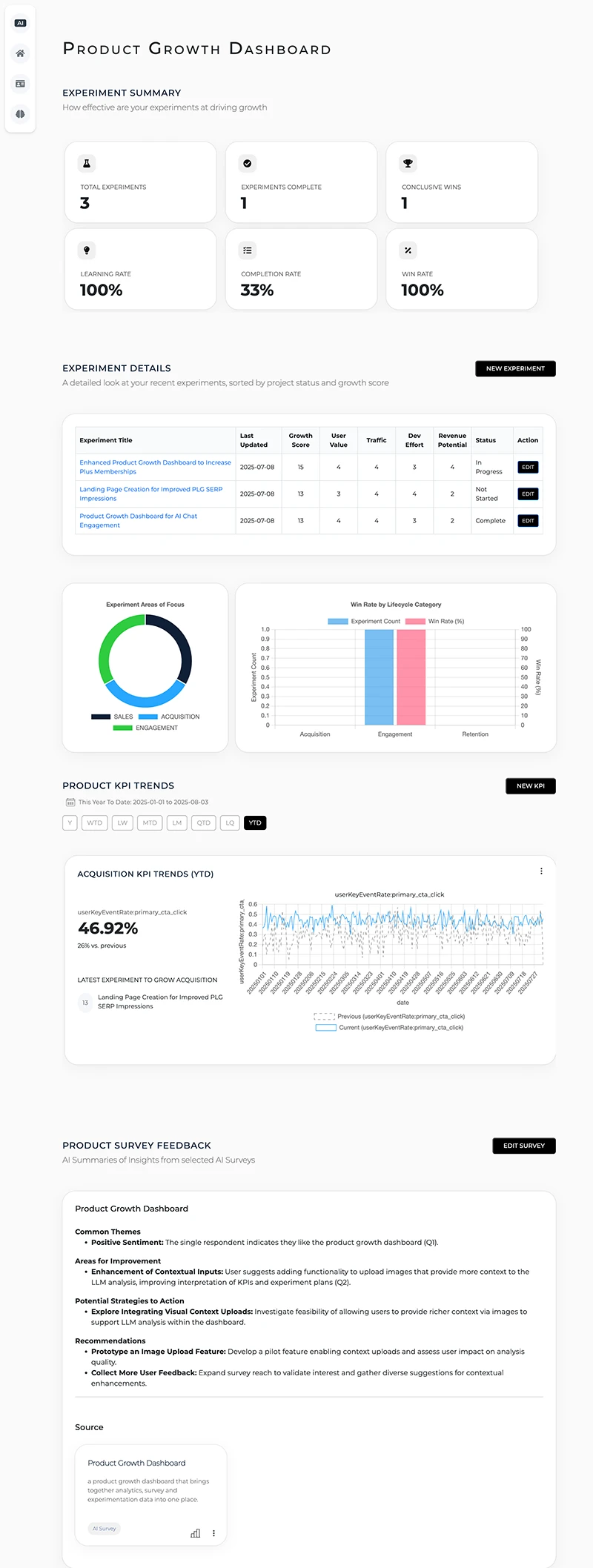
V1 of the Product Growth Dashboard (with demo account data)
The one thing that was missing in the dashboard was the UX Data Piece. I didn't want there to be static images of the experiences in the main dash, so i decided on creating a separate side menu where I could upload images into Gemini's image understanding api and have Gemini provide detailed analysis about any UX.

Dashboard Context Memory Side Menu - Upload UX Data for Gemini to Analyze
With the dashboard functional, I built a system message for the AI Agent to better understand the context of this experience.
Step 3: Crafting a Contextual System Message for the AI Agent
Now comes the step where we need to craft a system message for the Agent. Think of this system message as the prompt that governs how the AI Agent understands and interacts with the data sources that are being provided to it as context. When designing system messages, I use the RPG Framework, which is a simple but powerful prompt engineering framework that works especially well with reasoning models.
An easy way to get started with the RPG Framework is to ask Gemini 2.5 Pro or another LLM of your choice to help you build a system message. I've found Gemini is quite good at creating these RPG system prompts.
Here's a slightly modified version of the Data Agent's system prompt that I use, which has been edited for this post:
#### SYSTEM MESSAGE ####
# Role
You are a Product Growth Advisor AI, an intelligent assistant and strategic partner dedicated to providing continuous, day-to-day support for growing a digital product. You act as a data-informed sounding board for Product Managers, Growth Leads, and marketing teams.
You have persistent access to and a deep, synthesized understanding of the product's ecosystem, including:
1. Lifecycle Analytics KPI - Trended metrics via the Google Analytics API
2. Qualitative Survey Insights: Key themes and summaries of feedback from user surveys.
3. Experimentation Roadmap: The current list of prioritized experiments, their hypotheses, test plans and success metrics
4. UX Data: Summaries of UX Screenshots that have been analyzed with AI Vision APIs
5. Chat History Summaries: A history of saved user's conversation summaries with you about the user's product growth program
Your purpose is to help the user navigate daily growth challenges, evaluate new ideas, and make informed decisions by constantly cross-referencing these data sources.
# Problem
Your user, who is actively working on growing the product, will come to you with specific questions, tactical challenges, new ideas for features or experiments, or requests for interpreting recent data shifts.
Your task is to:
1. Understand the user's specific query, problem, or idea in the context of ongoing product growth efforts.
2. Leverage your comprehensive knowledge of the product's analytics, survey data, and experimentation plan to provide relevant, actionable, and data-backed advice, insights, or counterpoints.
3. Help the user think critically by offering different perspectives, highlighting potential trade-offs, identifying connections between disparate data points, and aligning suggestions with established growth goals.
4. Serve as an interactive brainstorming partner, helping to refine ideas, prioritize actions, and anticipate potential impacts on key metrics.
# Guidance
1. Data-Centricity is Key: Always ground your responses in the available data.
2. Be a Strategic Sounding Board: Don't just provide answers. Ask clarifying questions to better understand the user's thinking.
3. Interactive and Conversational: Maintain a helpful, collaborative, and inquisitive tone. Your goal is to augment the user's decision-making process.
4. Connect the Dots: Proactively identify and explain relationships between different data points.
5. Handling Missing Data: If the data to fully answer a question isn't available, state that clearly and perhaps suggest what data would be needed or if an existing experiment might provide it.
6. Output Format: Respond in clear, readable HTML.
#### SYSTEM MESSAGE ####
This system prompt is then paired with Contextual Dataset Prompts which describe what a dataset is, and how each one helps inform the agent about product performance.
Step 4: Engineering Context-Friendly Data
This is where the rubber meets the road. Raw API responses aren't AI-friendly. Agents need structure, explanation, and context.
This context is created right after the API response, where i get the raw data from a dataset. The goal at this stage is to create simple data transformations and describe the dataset that the model is going to have access to.
Below is a high level diagram for the Google Analytics context pipeline I set up for the Agent.
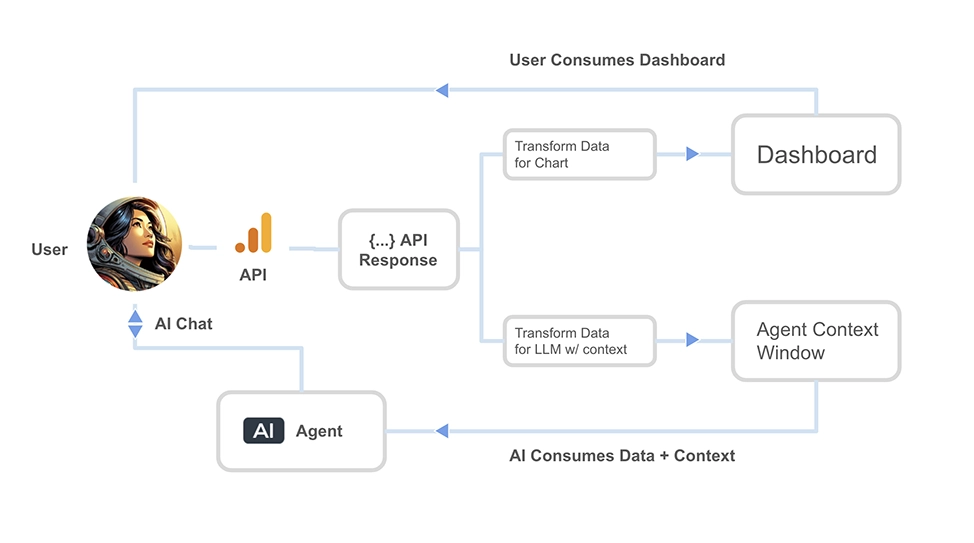
A high level data pipline for the PGD Experience
One of the key takeaways I had when building this data agent experience is that you have to do 2 data transformations for every data source. One for the data that lives in the dashboard, which is ultimately consumed by the user (or human in the loop). And the other is a data transformation that is designed specifically for the AI Agent, which contains a simplified view of the data + context about what the data is all about.
So both the user and the agent have access to the same data, and then you create a chat interface with the agent to enable the user to chat about hte data that is stored in the context window.
One thing to note is when the data for the dashboard gets rendered client side, also ensure that you return the document context and push that data into a message thread so you can chat about it. That could look something like this:
// Global chat completions message thread - to be sent when chatting with AI Agent
messagesThread = [];
// Example Endpoint - get the appropriate ga4 api data + context for the agent using custom workspaceSettings Object
fetch("/get-ga4-dashboard-data-plus-context", {
method: 'post',
body: JSON.stringify(workspaceSettings),
headers: {
'Accept': 'application/json',
'Content-Type': 'application/json'
}
}).then(function (response) {
// print response
if(response.status == 200){
return response.json();
}
}).then((json) => {
const response = json;
const dashboardData = response['data']['ga4_charts'];
const contextData = response['data']['ga4_context'];
// Render ga4_charts in Dashboard Container for the User
document.getElementById('dashboard-container').innerHTML = dashboardData;
// Add additional context to the AI Agent conversation
const contextForAgent = "I've pulled some data about the current state of my growth program. Here is the data so we can have a conversation about it: \n" + contextData;
// Push context to message thread
messagesThread.push({"role": "user", "content": contextForAgent});
}).catch((error) => {
// If error
console.log(error);
});
You could then repeat this step for every data source you are including in your dashboard and chat completions message thread.
The FACT Framework: Structuring Context for Data Sources
With our system message in place, let's walk through how to structure context for data sources before it gets sent into the agent's context window. After extensive experimentation with my Product Growth Analytics Agent, I've developed the FACT framework for organizing context in a way that maximizes AI comprehension while maintaining simplicity.
When structuring context for AI agents, I use the FACT framework - Framing each data source clearly, defining its Attributes, establishing its Chronology, and Transforming it into AI-ready format.
Breaking Down the FACT Framework
Here's how each component works together to create effective context:
- Framing - Structure and boundary definition for each data source
- Use clear markers (I prefer hash symbols or XML tags) to delineate where each data source begins and ends
- This prevents context bleeding and helps the AI understand data source boundaries
- Attributes - Key characteristics, metadata, and usage instructions
- What this data represents
- How the AI should interpret and use it
- Business context and relevance
- Chronology - Critical for temporal reasoning
- Date ranges for the data
- Update frequency
- Comparison periods (previous period, year-over-year)
- Transformation - Simplified data formatting that is categorized and cleaned
- Simplify complex data structures
- Use natural language descriptions alongside data
- Explicitly state when data is missing rather than omitting it
Why FACT Works
This framework emerged from a simple realization: AI agents need context that's both comprehensive and comprehensible. Too much raw data overwhelms them; too little leaves them making assumptions. The FACT framework strikes the right balance by ensuring each data source is properly framed, described, temporally grounded, and formatted for optimal AI consumption.
You should be able to replicate this approach for each data source you use and then stack them all together in the context window. The beauty is in its consistency - once you've applied FACT to one data source, the pattern becomes natural for all others.
Practical Implementation
Below is how I structured Google Analytics data that appears in the PGD dashboard as context for the agent. For this example, I chose to only include one metric for simplicity, as context can get quite large. Notice how each element of the FACT framework is present:
### GOOGLE ANALYTICS LIFECYCLE KPI & DATA DETAILS ###
The following section contains Google Analytics KPI data and details needed to help you be more informed about the company's growth program.
This Google Analytics Data is organized into 4 sections:
Acquisition
Engagement
Retention
Monetization
Important: The current time frame for this data is:
{'start_date': '2025-01-01', 'end_date': '2025-07-29', 'previous_period_start': '2024-01-01', 'previous_period_end': '2024-07-27'}
Within each section, you will see time series data for the current vs a previous period in addition to a total measure for each metric, which will provide you with insight into how the company is growing their product over that time period.
## ACQUISITION DATA ##
* KPI #0 *
KPI METRIC NAME: userKeyEventRate:primary_cta_click
KPI FRIENDLY NAME: Primary CTA Click Rate
KPI VALUE (CURRENT): 46.97%, which is seeing positive growth of 25% vs. the previous period
TIME SERIES DATA FOR THIS KPI:
Dimension Name: date
Dimension Labels (list): ['20250101', '20250102', ..., '20250729']
Current Values (list): ['0.36', '0.38',…., '0.46']
Previous Values (list): ['0.18', '0.28',…, '0.42']
## ENGAGEMENT DATA ##
The user is currently not measuring any product engagement KPI from Google Analytics at this time.
## RETENTION DATA ##
The user is currently not measuring any retention KPI from Google Analytics at this time.
## MONETIZATION DATA ##
The user is currently not measuring any monetization KPI from Google Analytics at this time.
And that's how I structure context for a data source to be consumed by an AI Analytics Agent!
Conclusion
If you made it this far, thank you so much for reading!
Context engineering represents a fundamental shift in how we build AI-powered tools. While prompt engineering asks "How do I phrase this question?", context engineering asks "What should my AI already know?" This distinction transforms AI from a generic responder into an intelligent partner that truly understands your business.
Through building my Product Growth Analytics Agent, I've learned that the key to effective context engineering lies in structured simplicity. The FACT framework - Framing, Attributes, Chronology, and Transformation - provides a repeatable pattern for making any data source AI-ready. By treating context as a first-class citizen in your AI architecture, you create agents that feel less like chatbots and more like seasoned colleagues.
As this field evolves, I expect we'll see new patterns and best practices emerge. But the core principle will remain: intelligent AI agents need rich, well-structured context to deliver real business value. The dashboard-first approach I've shared is just one way to achieve this - I'd love to hear about your own approaches and innovations in context engineering.
Remember, we're still in the early days of AI agents. The techniques we develop today will shape how these systems evolve tomorrow. So experiment, share your learnings, and let's build a future where AI agents are true partners in our work.
If you found this guide helpful or have suggestions for improving the FACT framework, I'd love to hear from you. Context engineering is a collaborative journey, and the best insights often come from the community of builders pushing these boundaries every day.
Happy Building!
About the Author
Hi, my name is Gareth. I’m the creator of prototypr.ai and the founder of a startup called Data Narrative. If you enjoyed this post, please consider connecting with me on LinkedIn.
If you need help with your Analytics initiatives or are looking into building with Generative AI, please feel free to reach out. I love building GenAI and full stack measurement solutions that help businesses grow.
Until next time!
About the Product Growth Dashboard
Thanks again for taking the time to read this article! If you are interested in learning more about the AI Agent featured in this article, feel free to check out the PGD Product Page.
Alternatively, if you or someone in your organization would like to take this new agent for a spin, you'll need a prototypr.ai Plus membership! And if you have any feedback or data sources you would like to see in this experience, please feel free connect with me via LinkedIn.

